Are There Alternatives to Using Consumer Credit Scores for Insurance Underwriting and Rating?
Going back to at least the mid-1990’s, insurance companies used consumer credit scores to make decisions on underwriting risk and eligibility, insurance rating, program tiering, and other applications.
However, today’s privacy-minded consumer is demanding protection for their personal information, and as a result, insurance departments are regulating how they access and use that data.
In addition, with the explosion of AI and machine learning applications, protecting private information is becoming more challenging, and insurance regulators are now faced with how to protect consumers from the errant use of these emerging technologies.
Three states—California, Hawaii and Massachusetts—no longer permit insurance companies to use customer credit scores in their underwriting and rating plans.
So, what steps can insurance companies take to find a replacement for customer credit score before more insurance regulators decide this information is no longer permitted for use in underwriting or rating?
How Credit Scores Factor into Insurance Scores
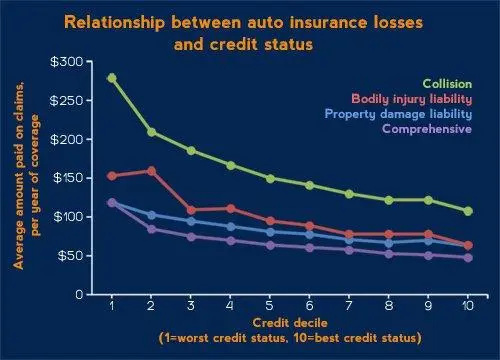
For automobile insurers, customer driving history will always be used to inform the risk one driver represents over other drivers with better driving histories. Carriers already collect a lot of data on other driver attributes such as type of vehicle, use of vehicle, average miles driven to work, age of driver, marital status, lease or ownership of vehicle, number of operators, and many others.
Similarly, for homeowners’ insurance, there is widespread use of customer credit scores to determine eligibility and rating.
Interestingly, customer credit is not as strong a predictor for claims frequency in homeowners’ insurance as it is for automobile insurance. One obvious reason for this is that many claims are caused by weather events that are completely uncorrelated to customer credit.
Credit Score Alternatives for Insurance Ratings
The good news is that most insurers already gather enough data to find proxies that are accurate and effective in predicting claims frequency.
Through the advent of advanced analytical tools, the actuary or analyst can study experience data (i.e. frequency of claims) with multiple customer attributes and search for correlations among data that previously went undiscovered. Using control studies with their own data, they can determine how precise their predictions will be when certain customers attributes exist.
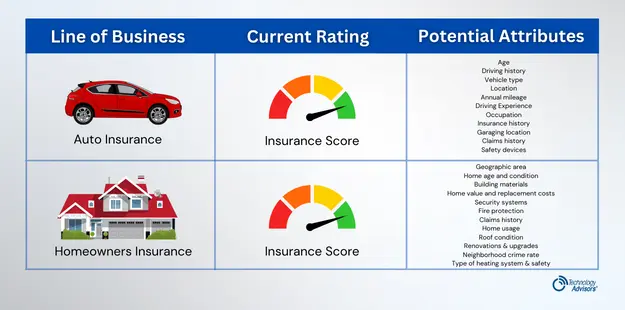
With homeowners’ insurance for example, there are similar attributes that have proven to be better proxies for consumer risk. One such attribute is roof condition. There are gradations of roof condition that can be ranked, for example as New, Good Condition, Moderate Condition, or Poor Condition. In this example, there are four categories of roof condition, but an analyst may decide there are actually eight conditions depending on how detailed their data collection process is.
As with the auto example above, the carrier experience data should be pulled in for a side-by-side controlled study for the purpose of making predictions on future underwriting using this single attribute (i.e. roof condition).
These are just two simple examples of how data already collected by a carrier can be leveraged to get ahead of competitors and regulators before there are limits placed on the use of customer credit.
A Structured Approach to Data Analysis
Consumer credit ratings are certainly helpful for understanding behaviors and patterns, but insurance companies aren’t confined to them. Because carriers already collect so much diverse data, they have many other insights available for analysis.
The first step in uncovering these insights is to centralize all relevant data into one location so it can be cleaned and prepared for analytical applications. Many carriers use CRM systems for this purpose, as they are natural repositories for organized customer data.
Once the information is consolidated and organized, insurance carriers must work to find connections and relationships between various customer attributes and how they relate to frequency and severity of loss.
Often, there are obvious and powerful correlations between ordinary customer attributes and frequency and severity that go missed. Centralized data helps uncover those insights and feed them into reporting and analytics resources that unearth the meaning behind the data points. Hence, this centralization of data in a solution like CRM is important, and carriers must assess their current technology stack to determine where they stand.