Wildfire Risk Assessment: A Data-Driven Approach for Insurance Actuaries
Statistical Models for Wildfire Risk Assessment
When it comes to wildfire risk assessment, the insurance sector has predominantly leaned towards statistical models, renowned for their simplicity, transparency, and interpretability. These models offer a straightforward approach to gaining approval from regulatory bodies to say “No” in the face of changing risks.
Statistical models analyze historical data and create large numbers of hypothetical events. Sometimes referred to as experience studies, statistical models seek to identify patterns and trends in historical data.
Observed data is used to estimate parameters, but statistical models are not location specific and remain static simulations. They use the power of computers to evaluate many possible future events occurring, without regard to current conditions.
The concept of a 100-year event hinges on the capacity of statistical models to assign probabilities to hypothetical scenarios. However, with shifting global conditions, there’s an increasing realization that what were once considered rare events are now occurring more frequently. This suggests that the traditional understanding of a 100-year event occurring once in a century is no longer true. As the dynamics of our planet continue to evolve, insurance actuaries must recalibrate their analytical strategies to adapt to the new reality.
Probabilistic Models for Wildfire Risk Assessment
Probabilistic models, also known as stochastic models, explicitly model uncertainty using probability distributions. They offer flexibility, scalability, and principled reasoning in the face of a changing world.
Forward thinking insurance actuaries can use AI and machine learning to leverage the power of probabilistic modeling, extract valuable insights in the face of uncertainty, and make informed decisions.
These data models offer several advantages over pure statistical models, including the ability to model complex dependencies among variables, incorporate prior knowledge into the modeling process, and propagate uncertainty through the model structure.
Probabilistic (or stochastic) models are well-suited for tasks that require principled reasoning about uncertainty, such as decision-making under uncertainty, probabilistic reasoning, and Bayesian inference. However, probabilistic models are computationally intensive and require large amounts of data to accurately estimate model parameters.
Comparing Probabilistic and Statistical Models
While both probabilistic models and pure statistical models share the common goals of interpreting data, there is a key distinction in their treatment of uncertainty.
Probabilistic models explicitly model uncertainty using probability distributions, allowing for principled reasoning about uncertainty and decision-making. In contrast, pure statistical models treat uncertainty as a feature of the data and rely on sampling variability to quantify uncertainty in estimates.
Another important distinction between probabilistic models and pure statistical models is their treatment of parameters. In probabilistic models, parameters are typically treated as random variables with prior distributions, which are updated based on observed data using Bayesian inference. This allows for flexible modeling of complex data dependencies and incorporation of prior knowledge into the modeling process.
In contrast, pure statistical models treat parameters as fixed but unknown values, which are estimated from the data using frequentist estimation techniques. While this approach provides unbiased estimates of parameters under certain conditions, it may lead to overfitting and lack of robustness in complex modeling scenarios.
While probabilistic models offer flexibility, scalability, and principled reasoning about uncertainty, pure statistical models provide simplicity, transparency, and less nuanced interpretability.

Athena Intelligence: A Probabilistic Use Case
Athena Intelligence is a data vendor with a geospatial, conditional, profiling tool that pulls together vast amounts of disaggregated wildfire and environmental data to generate spatial intelligence, resulting in a digital fingerprint of wildfire risk.
Athena Intelligence’s Voice of the Acre®, while falling under the umbrella of probabilistic modeling, distinguishes itself with its integration of geospatial analysis which reflects changing conditions. With conditional profiles, Athena’s prefire model generates probabilistic projections of the risk of a catastrophic wildfire in the next 12 months.
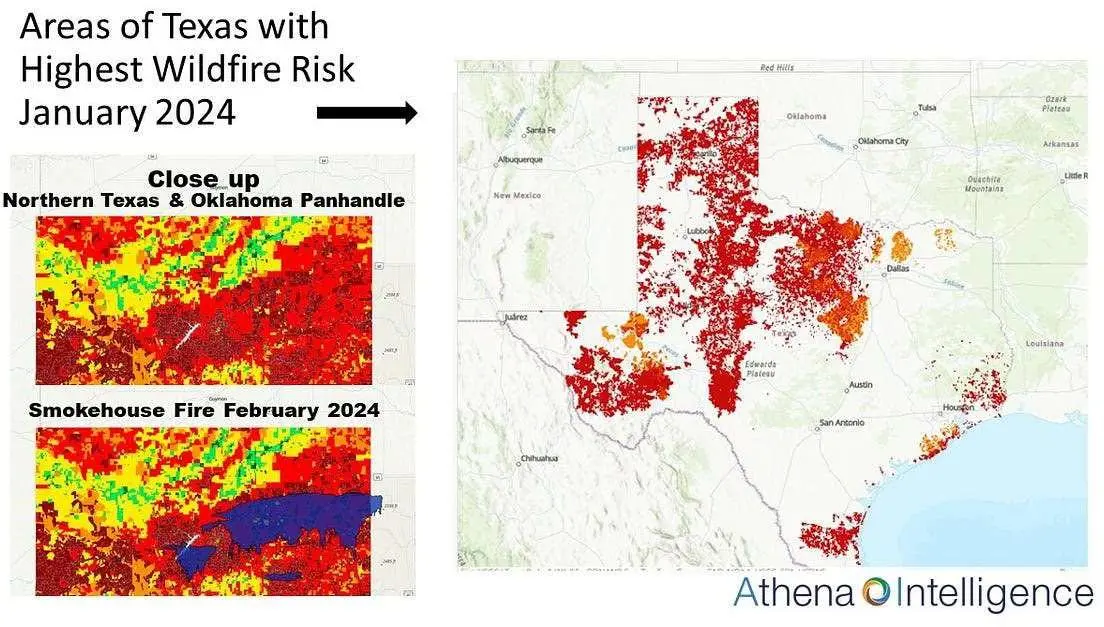
The model looks at the conditions of the land just before actual wildfires, using historic information and a probabilistic risk model to create conditional profiles. Athena’s wildfire algorithm uses no hypotheticals, but rather incorporates all the information that relates to wildfires and their propensity to spread, for miles around a pixel (a 30 sq meter location). Then this profile is compared to profiles in and around historic wildfires in a bioregion to create a conditional, probabilistic assessment of risk.
Thus, using Athena for wildfire risk, an insurance actuary can say, “In past fires, this set of conditions on the land occurs in 50% of all Texas wildfires. Therefore, ANY Texas property with these conditions, can only be insured with a high premium.” In a location where these conditions exist, but there is no history of wildfires, statistical models may find the property to be low risk.
Ultimately, Athena’s stochastic model shows a direct correlation between actual fires and current conditions at a specific location, even if no fire has occurred in that location.
Comparing Models: Which is Better for Assessing Wildfire Risk?
With climate change altering how we assess risk, probabilistic models offer a more adaptive and thorough tool for insurance companies. These models are crucial not only for setting premiums but also for conducting stress tests, optimizing risk portfolios, and pricing reinsurance.
However, sometimes it’s not possible to get access to the rich volumes of experiential data necessary for a robust stochastic model. In this case, it may be advisable to use a statistical model using parameter estimators that are fixed.
Optimizing Data Management in Insurance: The Role of CRM Systems
Whether an insurance actuary is relying on statistical or probabilistic analysis, collecting, organizing, and processing data is necessary. Here, it is recommended using a CRM to serve these functions. A CRM acts as a centralized platform to store all data. This consolidation makes it easier to access and manage information, reducing the complexity and time involved in gathering data from disparate sources.
By centralizing data, CRMs help maintain consistency and accuracy across data sets. They often include features that minimize duplication and allow for the cleaning and standardization of data, which are critical for reliable data analysis.
CRM systems are also designed to scale, accommodating an increasing amount of data and more complex data analysis needs without compromising performance.
Understanding both statistical and probabilistic models helps us better mitigate the increasing risks associated with wildfires, making our approach to insurance more precise and responsive to a changing world. Using a CRM to collect and organize data ensures the accuracy and reliability of those analytical models for the long-term.